Lockdowns, travel bans and restrictions linked to pandemic situation here and there… these last 2 years were a great opportunity to do “home sailing”. I am now hoping for the best to put all that into practice !

My little library for sailing

Lockdowns, travel bans and restrictions linked to pandemic situation here and there… these last 2 years were a great opportunity to do “home sailing”. I am now hoping for the best to put all that into practice !
My little library for sailing
Last month I went to Antibes and got this certification after a short training with Zephyr Yachting. No sailing so to speak, but still very interesting to learn and understand the handling of a small tender with an outboard engine, and useful.

PowerBoat Lvl2 Certificate
Completed with NavAtHome !

This year, I achieved my objective by completing the Day Skipper practical course successfully in the South of England with Hamble Point Sailing School. The training, which took 5 days, started at Hamble Point marina. The 115NM journey brought me to Yarmouth, Portland harbour, then back to the Solent via the Needles, to East Cowes, and to Gosport near Portsmouth, with plenty of opportunities to practice gybing, tacking, anchoring, berthing, motoring, navigating, piloting, MOB, and… cooking !
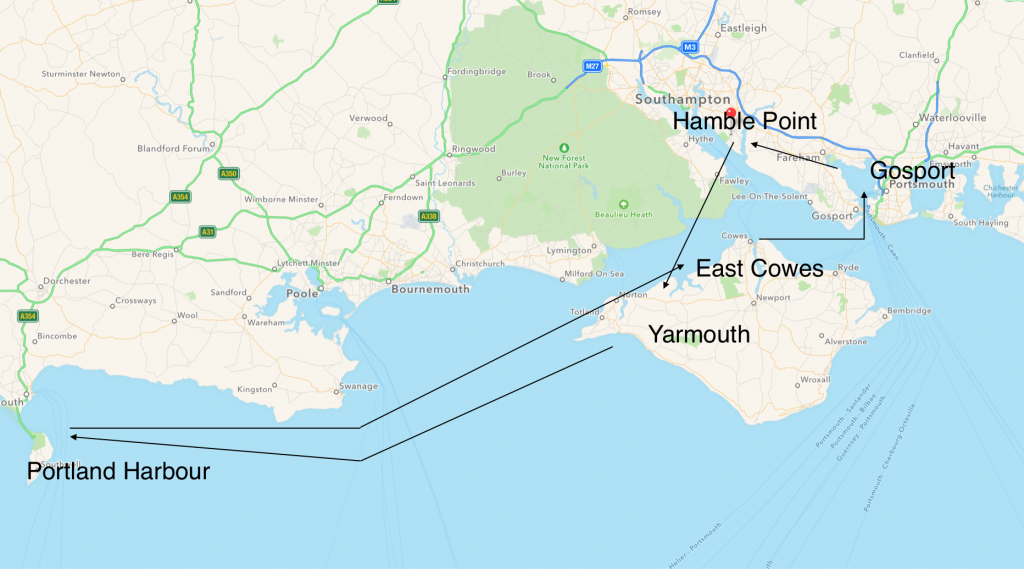
A 115NM-round trip South of England

Day Skipper Course Completion Certificate
The 9th May, I completed successfully the delivery of the Santa Maria. After many adventures, she is now there, sitting at home !
I bought the kit (Artesania Latina) in September 2008, it took me only 11 years to make it… better late than never.

Santa Maria
After my Competent Crew in June, I decided to get some sailing experience as a crew on a 2002 Jeanneau Sunfast 37 (‘Desert Star’) by going on a 375-mile trip in the Irish Sea with Irish Offshore Sailing, a school based in Dun Laoghaire that I know very well. This trip lasted 7 days and I could visit small harbours in Scotland, Isle of Man, Wales and Ireland. The weather was good, there was no rain and some good wind (up to 20 knots). An invaluable experience that I won’t forget ! Next objective : the RYA Day Skipper certification, scheduled for next year…
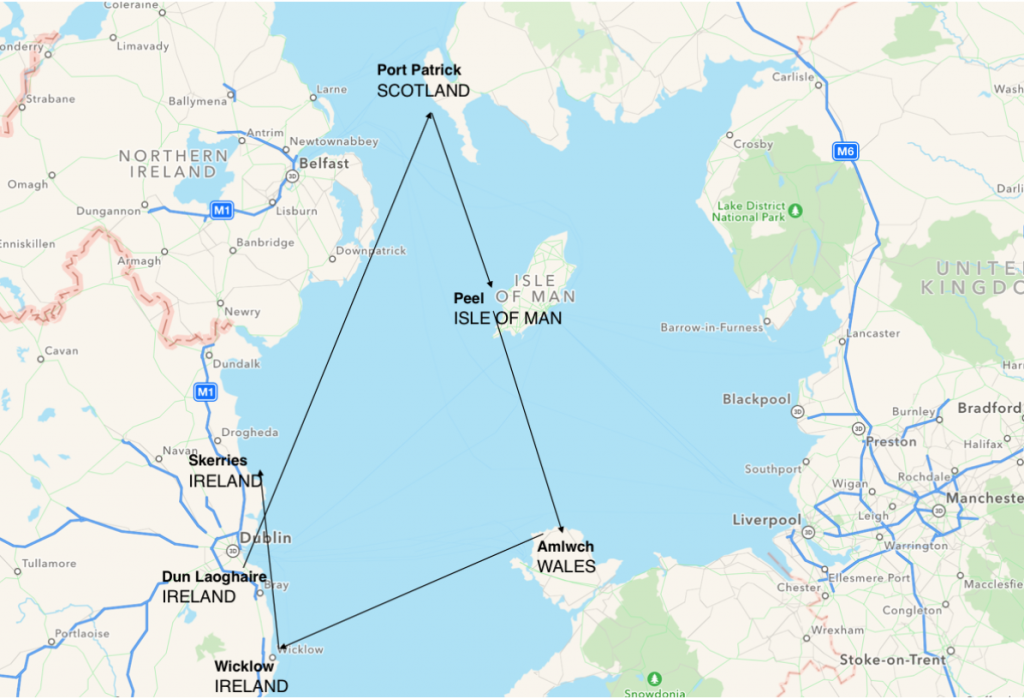
A 375nm-round trip in the Irish Sea
After some delays due to cold temperatures, I could finally complete my Competent Crew certification with MOSS sailing school, based in Medemblik in the Netherlands. In 5 days, I could learn the basics of sailing, enjoy great weather conditions and visit some of the many marinas of the Ijsselmeer and Waddenzee : Medemblik, Stavoren, Hindeloopen, Harlingen, Texel and Den Helder. A very instructive week, I am really glad I have reached my objectives !

Completed with NavAtHome !

More than a year ago, I started sailing in Dun Laoghaire, at the Irish National Sailing School, on a 1720 keelboat. Besides discovering the harbour and its surroundings from the Dublin Bay, which was great fun, I also took it seriously to study and learn about seamanship.



Kurzweil’s book, written in 2012
Our Universe exists because of its informational content. From pure physics to chemistry and biology, evolution started from simple structures (atoms, carbon molecules…) to create more complex ones (DNA, proteins…), and life eventually ! This evolution yielded nervous systems and finally the human brain, which is able of hierarchical thinking. The neocortex is the central piece, it can work with patterns, associate symbols and link them together to give rise to the knowledge that we know. Technology is nothing else but applied knowledge being made possible by humans ability to manipulate objects and make tools. Reverse-engineering the brain to make thinking machines is probably the greatest project ever, one that can transcend humankind.
Even though this book is certainly not the expression of a real scientific work, it is full of optimistic insights and bewildering intuition on future. It is amazing to see how technological progress transformed our societies these last few decades, and we are possibly the witnesses of a major transition never seen before which is going to change humankind forever. Thinking machines able to compete with humans should appear by the 2030s. A natural consequence of LOAR (Law Of Accelerating Return, a postulate stating that evolution accelerates as it grows in complexity and capability) is that humans and machines will meld together, and the computing limits will probably be reached at the end of the century, giving rise to a deeply transformed society potentially able to colonise space and conquer new solar systems.